

In the rush to play in the Big Data game, it’s easy to forget the fundamentals. The fear of being left behind can cause enterprise IT teams to move directly into pilot projects with a choice of products and technologies that may not be best designed to solve the identified business problem. For example, because Hadoop has become such a popular tech buzzword, many organizations are racing to implement this Big Data platform before properly understanding their goal. A mismatch can often result.
The confusing, emerging world of Big Data is not doing IT any favors, either. With literally hundreds of products and technologies already in the market (and more announced monthly), each claiming to best address the new opportunity presented by the volume, velocity and variety of Big Data, it’s no surprise that corners are being cut. The good news is that many excellent products and technologies now exist to enable fast, efficient, affordable and sophisticated use of even the largest and most dynamic big data sources. The bad news is that there are so many products already in this space that finding the right combination to suit a particular project requires either enormous research or just plain luck.
Fortunately, many analyst firms and technology educators are working overtime to help make sense of all the product releases, claims and rhetoric. Recently, the 451 Group provided a series on Big Data, helping to simplify some of the complexity inherent in this fast-paced new market. In his piece titled “NoSQL, NewSQL and Beyond,” analyst Matt Aslett begins to categorize and explain the differences between a wide variety of offerings and includes some helpful diagrams along the way. Forrester continues to offer a wide array of keen insight on the Big Data market, chronicling its expertise into reports and blog entries. And O’Reilly Media has produced a series of books and coursework for the data science practitioner.
Back to Basics
I believe that Big Data represents not a deluge but a huge opportunity. Research continues to be the best method to accurately understand the proper Big Data context and concepts, which remain fundamental. Then, we need to map all the Big Data possibilities. So I urge a return to the basics, which emphasizes solution-oriented thinking. As a start, I’ll provide an initial definition for several successful approaches to using Big Data. Not surprisingly, my taxonomy begins with the actual solution required (use-case-driven) and works toward the necessary enterprise architecture from there.
To derive a powerful snapshot of your best Big Data architecture or approach, you need to identify:
- A specific user profile
- A specific intended outcome or purpose for the data
- An ideal or required timeframe for processing the data
To identify this information, you should simply ask yourself:
- Who needs to use the data and do they need direct access to it?
- Why do they need to use the data (i.e., for what actions?)?
- How quickly do they need to use the data and how much latency can they absorb before the data starts to lose value?
Many IT organizations I’ve spoken with describe projects that align with one or more of three Big Data Approaches diagramed below. Let’s consider each in turn: Live Exploration, Direct Batch Reporting and Indirect Batch Analysis.
Three Approaches to Big Data Analysis
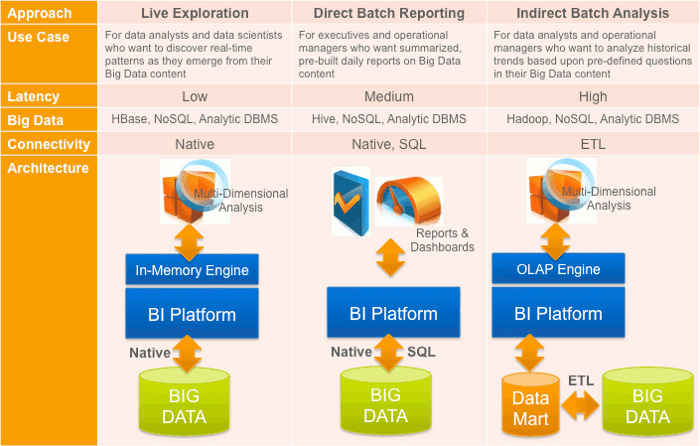
- Live Exploration is best for data analysts and data scientists who want to discover real-time patterns as they emerge from their Big Data content. This approach requires a low-latency architecture that uses native connections to the Big Data source. Within Hadoop, for instance, this means direct analytic and reporting access to HBase (or perhaps HDFS). For MongoDB or Cassandra, it would mean direct access to their equivalent underlying schema-less data stores.
Such access allows data to be potentially analyzed within seconds of being transacted and probably across more than a few dimensions. Initial construction of these exploratory queries requires the BI tool to provide a mechanism for complex (non-SQL) queries or its own metadata layer to map objects to native API calls, or both of these.
In this case, an in-memory engine combined with a suitable multi-dimensional analysis (end user) tool would work with the (ideally) de-serialized, filtered data to enable drag-and-drop pivots, swivels and analyses. Such a combination of intelligent data connection and BI platform architecture would enable an analytic experience very much like what is available working with traditional, relational (SQL-based) data sources.
For the sophisticated user, this approach can yield powerful insight from a variety of very high-volume, high-velocity data.
- Direct Batch Reporting is best for executives and operational managers who want summarized, pre-built daily reports on Big Data content. This approach uses a medium latency architecture whereby native file access is still an advantage (where possible), but traditional SQL-based querying can be sufficient.
Some Big Data sources have specialized interfaces for query access (SQL-based languages like CQL for Cassandra and HiveQL for Hadoop Hive) that make this use-case more straightforward, although the time required to compile, query and re-assemble the data for this approach lengthens the response time to minutes or perhaps hours.
Also, an analytic DBMS could be a popular choice in this architecture, as long as it supports the scale-out, high-volume read access so critical in a Big Data environment. The user could interact with a variety of data discovery tools, from simple or interactive reports and dashboards to richer analytic views — simply dependent on the project requirements.
This architecture can drive a more complete and relevant set of insight for a wider set of end users.
- Indirect Batch Analysis is best for data analysts and operational managers who want to analyze historical trends or mash up disparate data sources based upon pre-defined questions in their Big Data content.
This approach is probably the most popular early design for Big Data analysis because it uses ETL (extract-transform-load) techniques to overcome some of the limitations in the often schema-less data stores and append the data with richer metadata. Also, in this architectural approach, existing visualization and reporting tools can be used due to the traditional data interface support. Further, indirect batch reporting delivers the most flexibility but introduces substantially greater latency.
Therefore, this type of batch processing is best used for projects that have a well-understood set of questions to be uncovered using the Big Data. By normalizing the data (into a Data Mart or Data Warehouse), it becomes more capably combined (for analysis purposes) with traditional data sources. Most likely, a full OLAP engine and multi-dimensional end user tool will be warranted, to allow full-scale data exploration and discovery.
With this use-case, richness of insight and accuracy are more important than speed.
With Big Data Comes Big Responsibility
Big Data systems are generally recognized as those that provide massive scale-out capabilities, frequently with terabytes or petabytes of data, and are too expensive and unwieldy to manage with traditional systems. This shouldn’t mean that we abandon traditional approaches to matching the business requirements to the technology and solution.
With Big Data can come big insight … or big disappointment. Remembering the fundamentals and ensuring a solid alignment between the Big Data opportunity and the Big Data solution is the key to a successful project and delivering needed insight. I look forward to seeing future articles on Big Data begin emphasizing a variety of successful, referenceable projects within a variety of real organizations proving the newfound utility in this bold, new, Big Data world.









































Another great piece Brian!
Cool to see the industry finally adopting the "3V"s of big data over 11 years after Gartner first published them. For future reference, and a copy of the original article I wrote in 2001, see: http://blogs.gartner.com/doug-laney/deja-vvvue-others-claiming-gartners-volume-velocity-variety-construct-for-big-data/.
Also note that Gartner has produced over 400 research and advisory pieces concerning Big Data technology, techniques, roles, business uses, etc.
–Doug Laney, VP Research, Gartner, @doug_laney